Architecture
Microservices Architecture: A Practical Guide for 2026
I’ve spent the last eight years rebuilding platforms that got too big for themselves the kind of systems where a one-line change to the checkout page means a six-hour deploy and a prayer. Most of those rebuilds have ended in the same place: a microservices architecture. But “most” isn’t “all,” and that nuance matters more than the hype usually admits.
This guide is for the founder, CTO, or engineering lead trying to figure out whether microservices are right for their product and if they are, how to actually pull off the migration without losing a quarter of engineering velocity in the process. I’ve written it the way I’d explain it to a client over coffee: direct, specific, and opinionated where it matters.
TL;DR
Microservices architecture splits one big application into small, independent services that each do one thing and communicate over APIs. It makes your system easier to scale, easier to update, and more resilient but it also adds real operational cost. Use it when you have clear service boundaries, a team large enough to own them, and traffic that justifies the overhead. Skip it for early-stage products or simple CRUD apps a modular monolith will serve you better there.
What is microservices architecture?
Microservices architecture is a way of designing software as a collection of small, independent services that each handle one specific part of the system. Each service runs in its own process, owns its own database, and communicates with other services through well-defined APIs usually REST, gRPC, or asynchronous message queues.
The contrast is a monolithic architecture, where the entire application is one big codebase deployed as a single unit. Change anything, and you redeploy the whole thing. In microservices, you change one service and redeploy only that service. The rest of the system carries on.
That’s the textbook definition. In practice, microservices architecture is less about the technology and more about the organizational shift it forces: small teams owning small services end-to-end, with clear contracts between them. The tech follows from that.
Monolithic vs microservices architecture: when each actually makes sense
The monolith-versus-microservices debate gets treated as a moral question online, and it isn’t one. Both are valid. The question is which fits your situation.
Here’s the honest comparison:
| Factor | Monolith | Microservices |
|---|---|---|
| Initial build speed | Faster one codebase, one deploy | Slower distributed system from day one |
| Scaling | Scale the whole app together | Scale each service independently |
| Deployment risk | All or nothing | Isolated to one service |
| Team autonomy | Everyone in the same repo | Teams own their services |
| Operational cost | Low – one process to watch | High – many services, many pipelines |
| Debugging | Straightforward stack traces | Distributed tracing required |
| Database | Usually one shared DB | Each service owns its data |
| Best for | Startups, MVPs, small teams | High-traffic platforms, large teams |
If you’re a five-person startup shipping your first version, a monolith is almost always the right answer. If you’re an ecommerce brand processing 100,000+ orders a day with forty engineers across six teams, the monolith has probably become the bottleneck. Everything in between is a judgment call.
The core components of a microservices architecture
A working microservices system is more than just “a bunch of small services.” There are five pieces you need to think about before you write a single line of code.
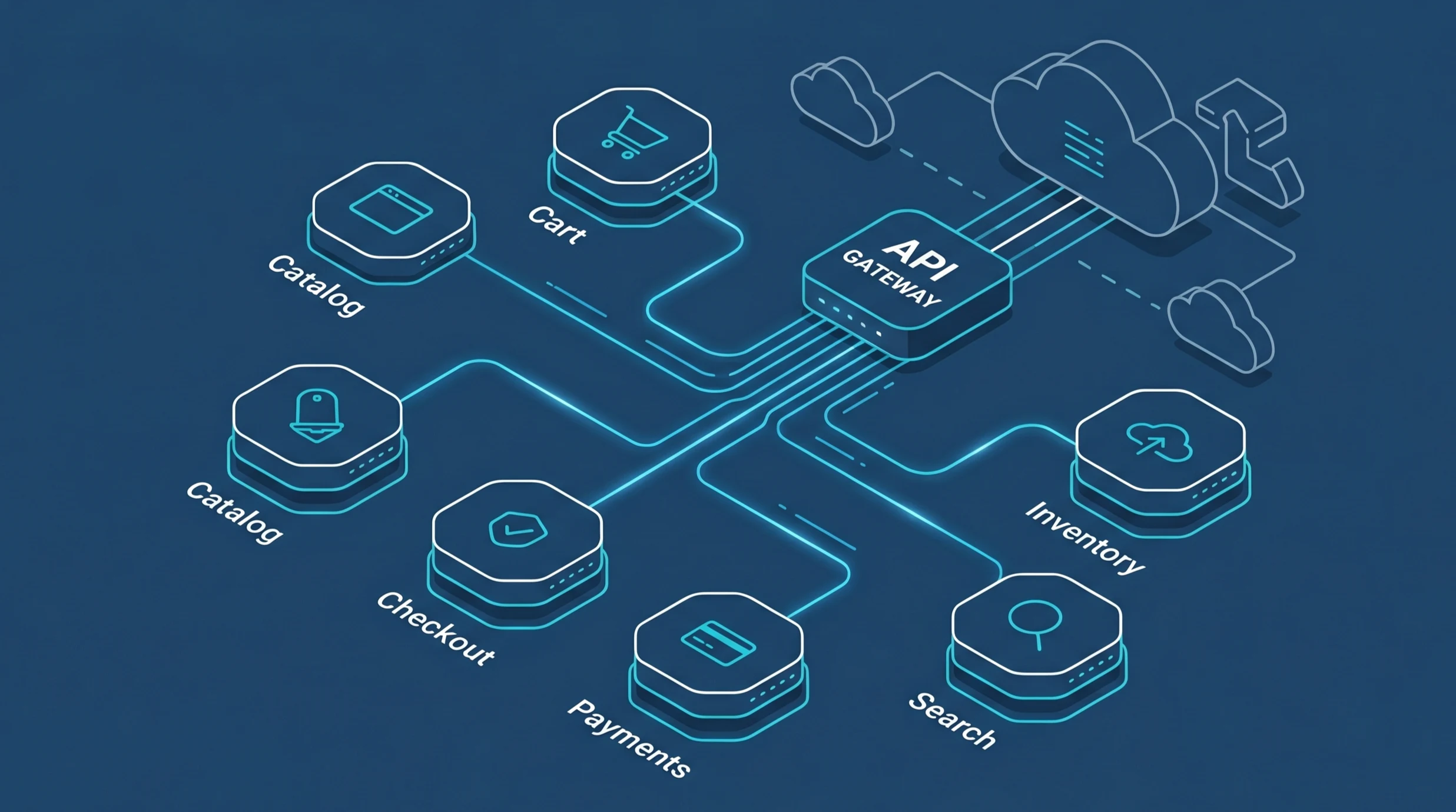
1. API gateway
The API gateway is the single front door for client requests. Instead of mobile apps and web clients talking to twelve backend services directly, they talk to the gateway, which routes each call to the right service. It also handles authentication, rate limiting, and response aggregation. Kong, AWS API Gateway, and Azure API Management are the common choices.
2. Service mesh
A service mesh handles the how of service-to-service communication retries, timeouts, circuit breaking, mutual TLS, and observability without each service having to reimplement that logic. Istio and Linkerd are the dominant options. You probably don’t need one until you have roughly ten services in production; before that, it’s complexity you haven’t earned yet.
3. Container orchestration
Each service runs in a container (Docker is the default), and Kubernetes orchestrates those containers across a cluster. Kubernetes handles deployment, scaling, health checks, and rolling updates. For smaller teams, managed Kubernetes on AWS (EKS), Google Cloud (GKE), or Azure (AKS) removes most of the operational pain.
4. Inter-service communication
Services talk to each other two ways: synchronously through REST or gRPC, or asynchronously through a message broker like Kafka, RabbitMQ, or AWS SQS. Synchronous is simpler but creates tight runtime coupling. Asynchronous is more resilient but harder to reason about. Most real systems use both, with async for anything that doesn’t need an immediate response.
5. Observability stack
With a monolith, one log file tells you what happened. With fifty services, you need distributed tracing (OpenTelemetry, Jaeger), centralized logging (Loki or the ELK stack), and metrics (Prometheus plus Grafana). Skipping observability is the single most common way teams regret going microservices don’t do it.
When should you use microservices architecture?
Use microservices when at least three of the following are true:
- Your team is larger than roughly 20 engineers, organized into distinct product areas
- Different parts of your system have genuinely different scaling needs (checkout vs search vs reporting)
- You deploy often daily or multiple times a day and the monolith deploy pipeline has become a bottleneck
- You have traffic patterns with sharp peaks (festive sales, Black Friday, viral spikes) that need independent scaling
- Failures in one part of the system regularly take down the rest
- You’re planning native mobile apps, a third-party API, and a web app that all need the same backend and that backend is getting tangled
If fewer than three of those apply, think hard before you commit. Microservices solve scaling problems by adding complexity problems, and the swap is only worth it when the first set hurts more than the second will.
When microservices are the wrong choice
I turn clients away from microservices roughly once a month. The situations where I do it most:
You’re pre-product-market fit
If you’re still changing the domain model weekly, you don’t know where the service boundaries should go. Drawing them too early is worse than not drawing them at all you’ll spend months untangling bad cuts. Ship a well-organized monolith, find product-market fit, then break it up when the pain justifies the effort.
Your team is smaller than ten engineers
A microservices system needs someone who owns observability, someone who owns deployment infrastructure, someone who owns each service, and someone keeping the whole thing coherent. With fewer than ten people you can’t staff that without everyone wearing six hats. That’s how small teams burn out.
Your workload is simple CRUD
If 80% of what your app does is create-read-update-delete on a handful of entities, the whole system is probably a few thousand lines of code. Microservices won’t make that simpler. It’ll make it an operations project.
You don’t have a CI/CD pipeline yet
Microservices multiply your deployment surface area. If you’re still deploying by SSH-ing into a box, fix that first. Without automated pipelines, testing, and rollback, microservices will make every incident ten times worse.
How to migrate from a monolith to microservices
Assume you’ve decided microservices are right for you. Here’s the migration pattern that actually works I’ve run this playbook on four platforms over the last five years, including a fashion ecommerce platform that was crashing at 10,000 concurrent users and now handles 100,000+.
Step 1: Map the monolith’s seams
Before you extract anything, map the existing system. Which parts of the code change together? Which parts rarely change? Which modules talk to which database tables? The natural seams you find usually along product areas like catalog, cart, checkout, payments are where your future services should live.
Step 2: Extract one service at a time
Pick the piece with the clearest boundary and the highest strategic value often checkout or search. Extract it into its own service, but keep the monolith running. The extracted service writes to its own database; the monolith reads from it through an API. Ship that, stabilize, then pick the next one.
Step 3: Use the strangler fig pattern
Named after the fig tree that grows around a host tree and eventually replaces it, the strangler fig pattern means routing new functionality to new services while gradually migrating old functionality. Traffic slowly shifts from the monolith to the services until the monolith is doing nothing and can be switched off. No big-bang cutover, no migration weekend, no disaster.
Step 4: Invest in CI/CD and observability before you hit ten services
You will feel the pain of weak tooling around the fifth service and the catastrophe of it at the tenth. Build the deployment pipelines, alerting, dashboards, and tracing infrastructure early. It feels like overinvestment at three services and like an obvious necessity at fifteen.
Step 5: Decompose the database last
The hardest part of any monolith-to-microservices migration is the shared database. Services should own their data, but extracting tables is slow, risky, and usually comes last. Until you do, accept the compromise: services talk through well-defined APIs even when they share some data underneath. Clean up the data ownership gradually.
Microservices architecture best practices
What separates a microservices rollout that works from one that turns into an expensive rewrite? A handful of disciplines, most of them boring:
Make each service own its data
No shared databases between services. If service A needs data owned by service B, it calls service B’s API. Sharing a database quietly recreates all the coupling problems you left the monolith to escape.
Version your APIs from day one
Services evolve at different speeds. Include a version in every endpoint (/v1/orders, /v2/orders) and keep old versions running long enough for clients to migrate. This is non-negotiable for public APIs and almost as important for internal ones.
Design for failure
In a distributed system, something is always failing somewhere. Use timeouts on every outbound call. Implement circuit breakers (Hystrix, Resilience4j) to stop cascading failures. Assume any call to another service can fail, and handle it gracefully.
Deploy independently
If deploying service A requires coordinating with service B’s team, you’ve built distributed monolith, not microservices. Each service should be deployable on its own timeline, with backward-compatible API changes until clients catch up.
Centralize cross-cutting concerns
Authentication, logging, rate limiting, and metrics should not be reimplemented per service. Push them into the API gateway, the service mesh, or shared libraries. Every team reinventing the same plumbing is pure waste.
Treat infrastructure as code
Terraform, Pulumi, or similar. Every piece of your infrastructure should live in a Git repository, reviewable and reversible. Click-ops doesn’t scale past three services.
Common microservices mistakes (and how to avoid them)
Splitting too early, too aggressively
The most common mistake I see: teams decide on microservices, then split their domain into twenty services before they have any real product usage. The service boundaries end up wrong, refactoring across services is harder than refactoring within a monolith, and the team burns out maintaining plumbing. Start with three to five services and let real usage tell you where the next cuts should go.
The distributed monolith
If your services can only be deployed together, if they share a database, or if a change in one requires changes in three others congratulations, you’ve built a distributed monolith. All the operational complexity of microservices, none of the independence. Usually happens because teams carve up the code without carving up the data.
Ignoring observability until it’s on fire
Teams that bolt on monitoring after the system is already struggling spend weeks trying to figure out what’s happening. Install distributed tracing, structured logging, and metric collection from day one. You will thank yourself.
Using HTTP for everything
Synchronous REST calls between services feel natural but create tight runtime coupling if service B is slow, service A is slow too. For anything that doesn’t need an immediate response (email notifications, analytics events, inventory updates), use async messaging through Kafka or RabbitMQ. Your latency and resilience will improve dramatically.
Real example: how microservices scaled an Indian fashion ecommerce platform 10x
A concrete example from a recent Dezdok project. The client was a leading Indian fashion ecommerce brand with 500,000 monthly visitors, running on a decade-old PHP monolith. Their symptoms were familiar:
- The platform crashed within 18 minutes of every Diwali sale going live
- Concurrent user capacity topped out around 10,000 demand was pushing past 100,000
- Mobile conversion sat at 1.4% against 75% mobile traffic
- Catalog updates took eight hours of manual work every day
We rebuilt it as a microservices system over six months. Seven core services catalog, cart, checkout, payments, inventory, search, recommendations each running independently on AWS EKS (managed Kubernetes), each owning its data, each scaling on its own.
The payoff came at Diwali 2024. The new platform handled 100,000+ concurrent users with 100% uptime. Mobile conversion moved from 1.4% to 3.8% – a 171% lift. Page load time fell from 5.2 seconds to 2.0 seconds. The checkout service, which gets hammered during sales, now scales independently from the catalog service, which gets hammered when the marketing team drops a newsletter. Neither blocks the other. The full case study is here: Fashion Ecommerce Platform Development worth reading if you want to see what a successful microservices migration looks like end-to-end.
Microservices technology stack: what we use at Dezdok
There’s no single “correct” stack, but these are the tools we reach for most often on microservices projects:
Languages and frameworks
Node.js with Express or NestJS for most services. Go for high-performance services (payments, real-time inventory). Python for anything ML-heavy. The choice per service is deliberate one of the few legitimate upsides of microservices is that each service can use the best tool for its specific job.
Containers and orchestration
Docker for packaging, Kubernetes for orchestration. Managed services (AWS EKS, GKE, AKS) over self-hosted unless there’s a specific reason to run your own control plane.
Data
PostgreSQL for transactional data. Redis for caching and session storage. Elasticsearch or OpenSearch for search. Kafka for event streaming between services.
Observability
OpenTelemetry for instrumentation, Grafana for dashboards, Prometheus for metrics, Loki for logs, Jaeger for distributed traces. Sentry for error tracking.
CI/CD and infrastructure
GitHub Actions or GitLab CI for pipelines. Terraform for infrastructure-as-code. Helm charts for Kubernetes deployments. ArgoCD for GitOps workflows.
Thinking about a microservices migration?
If your current platform is buckling under peak traffic, shipping slower than you’d like, or held together by a single senior engineer who understands how everything connects a microservices architecture might be the right call. It also might not. Either way, it’s worth having an honest conversation before you commit months of engineering time.
Dezdok has built microservices platforms for fashion ecommerce, D2C brands, and SaaS companies across India, the US, and the UK. We offer a free 30-minute technical audit where we’ll look at your current system and tell you whether microservices are the right move or whether you’d be better served by a modular monolith, a platform refactor, or something else entirely.
FAQs about Microservices Architecture
Usually not. Startups benefit more from speed than from independent deployability, and microservices trade one for the other. Start with a well-organized monolith. If you grow into a scale where the monolith becomes the bottleneck, extract services at that point. Companies that went microservices-first and survived did so because they had the funding to hire a platform team early — most startups don’t.
Fewer than you think. A good starting point is one service per clearly bounded business capability — typically 5 to 15 services for a mid-sized ecommerce or SaaS platform. Having hundreds of services is neither a goal nor a sign of maturity. It’s usually a sign the team over-decomposed early and can’t afford to consolidate now.
Service-oriented architecture (SOA) was the 2000s predecessor to microservices. Both split applications into services, but SOA typically shared a centralized enterprise service bus and large shared databases. Microservices emphasize decentralization: each service owns its data, there’s no central bus, and services communicate directly through lightweight APIs or message queues.
They mostly don’t — at least not in the traditional ACID sense. Cross-service transactions are handled with patterns like the Saga pattern, where each service performs its local transaction and publishes an event; if a later step fails, earlier services run compensating transactions. It’s more work than a monolithic database transaction, which is one more reason to keep service boundaries aligned with natural transactional boundaries whenever possible.
Not inherently — they change the security model rather than improve it. Microservices give you more isolation, but also more network surface area. You need mutual TLS between services, strict authentication at the API gateway, and a zero-trust mindset. A well-secured monolith is often safer than a poorly secured microservices system.
For a mid-sized ecommerce or SaaS platform, a full migration typically costs between USD 80,000 and USD 400,000 and takes six to twelve months. The range depends on catalog size, integration count, team experience, and how cleanly the monolith’s domain model maps to service boundaries. We give every client a fixed-scope quote after a free technical audit.

